php爬虫:PHP爬虫,从入门到实战,掌握网络数据抓取的核心技能
在当今数据驱动的时代,网络爬虫(Web Crawler)已经成为获取数据的重要工具,无论是数据分析、搜索引擎优化,还是商业情报收集,爬虫都扮演着关键角色,虽然Python因其丰富的库和简洁的语法成为爬虫开发的主流语言,但PHP作为一种广泛应用于Web开发的语言,同样可以胜任爬虫开发的任务,本文将带你了解PHP爬虫的基本原理、实现方法以及实际应用。
PHP爬虫的背景与优势
PHP是一种服务器端脚本语言,主要用于Web开发,虽然PHP在Web开发领域占据主导地位,但它在爬虫开发中也有独特的优势:

- 无缝集成Web开发环境:如果你已经熟悉PHP,那么在开发爬虫时可以轻松地将爬虫功能集成到现有的Web项目中。
- 丰富的HTTP库:PHP提供了多种HTTP请求库,如cURL、Guzzle等,可以方便地发送HTTP请求并处理响应。
- 文件处理能力强:PHP对文件的读取、解析和存储能力较强,适合处理HTML、XML等格式的数据。
- 跨平台性:PHP可以在多种操作系统上运行,且部署简单,适合快速开发和测试。
PHP爬虫的基本原理
PHP爬虫的核心原理是通过发送HTTP请求获取网页内容,然后解析内容提取所需数据,以下是爬虫的基本步骤:
- 发送HTTP请求:使用cURL或file_get_contents等函数向目标URL发送请求。
- 获取响应内容:接收服务器返回的HTML、JSON或其他格式的数据。
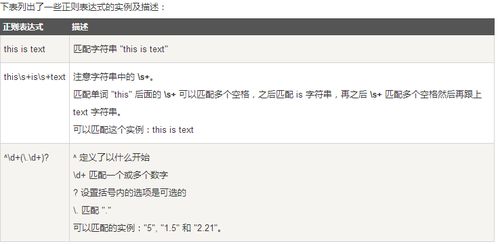
- :使用DOMDocument、SimpleHTMLDOM或正则表达式解析HTML结构,提取所需数据。
- 存储数据:将提取的数据存储到数据库或文件中,供后续分析使用。
PHP爬虫的实现步骤
下面我们通过一个简单的示例,展示如何用PHP实现一个基础的爬虫。

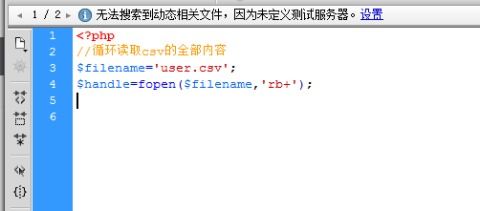
发送HTTP请求
<?php $url = 'https://example.com'; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); $response = curl_exec($ch); curl_close($ch); ?>
解析HTML内容
<?php
// 使用DOMDocument解析HTML
$dom = new DOMDocument();
@$dom->loadHTML($response);
$links = $dom->getElementsByTagName('a');
foreach ($links as $link) {
$href = $link->getAttribute('href');
echo $href . '<br>';
}
?>
数据存储
<?php
// 将提取的数据存储到MySQL数据库
$servername = "localhost";
$username = "username";
$password = "password";
$dbname = "myDB";
// 创建连接
$conn = new mysqli($servername, $username, $password, $dbname);
// 检查连接
if ($conn->connect_error) {
die("连接失败: " . $conn->connect_error);
}
// 插入数据
$stmt = $conn->prepare("INSERT INTO links (url) VALUES (?)");
$stmt->bind_param("s", $href);
$stmt->execute();
$stmt->close();
$conn->close();
?>
PHP爬虫框架与工具
为了提高开发效率,PHP社区也涌现出一些爬虫框架,以下是两个常用的PHP爬虫框架:
- Goutte:一个轻量级的PHP爬虫框架,基于Symfony的HttpKernel组件,适合简单的爬虫任务。
- PHP-Curl-Class:一个增强版的cURL类,提供了更简洁的API,适合处理复杂的HTTP请求和响应。
PHP爬虫的注意事项
- 遵守robots.txt协议:在爬取网站时,务必检查并遵守目标网站的robots.txt规则。
- 控制爬取频率:避免对目标网站造成过大压力,合理设置请求间隔时间。
- 处理反爬机制:一些网站会通过验证码、IP封禁等方式阻止爬虫,需要采取相应的反爬措施。
- 法律与道德问题:爬虫开发必须在法律允许的范围内进行,避免侵犯他人隐私或商业机密。
PHP爬虫虽然在灵活性和生态上不如Python,但其在Web开发环境中的优势使其成为一种可行的选择,通过掌握HTTP请求、HTML解析和数据存储等基本技能,你可以快速构建出功能强大的爬虫程序,无论是个人项目还是企业级应用,PHP爬虫都能为你提供高效的数据获取解决方案。
希望本文能帮助你入门PHP爬虫开发,开启你的网络数据抓取之旅!
文章已关闭评论!