oracle union用法:Oracle UNION用法详解,从基础到实战
UNION的基本语法
UNION的基本语法结构如下:
SELECT column1, column2, ... FROM table1 UNION SELECT column1, column2, ... FROM table2;
需要注意以下几点:
- 列数和顺序必须一致:每个SELECT语句中选择的列数、列名(或位置)必须相同。
- 数据类型兼容:对应列的数据类型应兼容,否则会报错。
- 默认去重:UNION会自动去除重复行,如果需要保留重复行,可以使用UNION ALL。
UNION与UNION ALL的区别
- UNION:合并结果集时会去除重复行。
- UNION ALL:合并结果集时保留所有行,包括重复行。
-- UNION会去重 SELECT 'A' FROM dual UNION SELECT 'A' FROM dual; -- UNION ALL会保留所有行 SELECT 'A' FROM dual UNION ALL SELECT 'A' FROM dual;
典型应用场景
合并两个表的数据
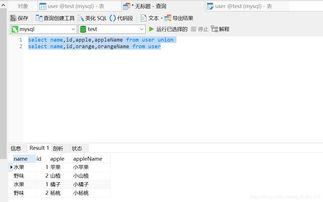
假设有两个表:employees和managers,结构相同,都包含employee_id和name列,我们想合并两个表的数据:

SELECT employee_id, name FROM employees UNION SELECT employee_id, name FROM managers;
横向合并不同表的数据
如果两个表结构相同,但存储的数据来源不同,可以使用UNION将它们合并:
SELECT product_id, product_name, price FROM north_products UNION SELECT product_id, product_name, price FROM south_products;
去重查询
UNION常用于去重查询,例如统计某个字段的唯一值:

SELECT DISTINCT department_id FROM employees UNION SELECT DISTINCT department_id FROM managers;
注意事项
- 性能问题:UNION操作需要对结果集进行排序和去重,可能会降低查询性能,尤其是在大数据量下,如果不需要去重,建议使用UNION ALL。
- 列名问题:如果每个SELECT语句的列名不同,结果集的列名将取第一个SELECT语句的列名。
- ORDER BY的使用:可以在最后的SELECT语句中使用ORDER BY对合并结果进行排序:
SELECT employee_id, name FROM employees UNION SELECT employee_id, name FROM managers ORDER BY employee_id;
- 子查询中的UNION:UNION不能直接嵌套在子查询中,但可以通过WITH子句(Oracle 11g及以上版本)实现:
WITH combined_data AS (
SELECT employee_id, name
FROM employees
UNION
SELECT employee_id, name
FROM managers
)
SELECT * FROM combined_data; 实际案例
假设我们有两个表:sales_2023和sales_2024,结构相同,都包含product_id、product_name和sales_amount列,我们想合并两个表的数据,并计算总销售额:
SELECT product_id, product_name, SUM(sales_amount) AS total_sales
FROM (
SELECT product_id, product_name, sales_amount
FROM sales_2023
UNION ALL
SELECT product_id, product_name, sales_amount
FROM sales_2024
)
GROUP BY product_id, product_name; 在这个案例中,我们使用UNION ALL保留所有数据,然后通过GROUP BY计算总销售额。
Oracle的UNION操作符是一个强大的工具,能够轻松合并多个SELECT语句的结果集,并自动去重,通过合理使用UNION和UNION ALL,可以高效地处理数据整合和去重需求,但在使用时需注意列结构、数据类型和性能问题,以确保查询的正确性和高效性。
希望本文能帮助你更好地理解和应用Oracle中的UNION用法!
相关文章:
文章已关闭评论!