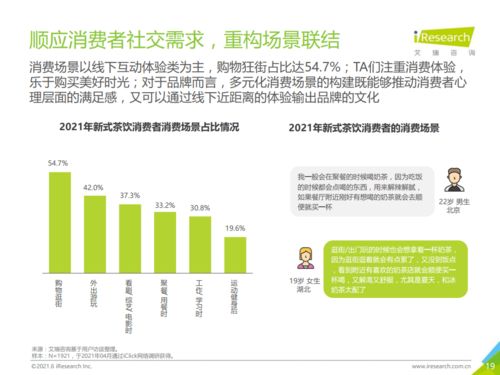
测智商:测智商,从纸笔到AI,一场跨越百年的认知革命
【导语】当阿尔法狗在围棋领域颠覆人类认知时,一场关于"人类智商是否可测"的争论再次爆发,从19世纪首次的心理实验到2024年的脑机接口技术,测智商技术正经历着从标准化纸笔测试到动态AI评估的范式革命。
智商测试的进化史 (1)萌芽阶段(1905-1930) 法国医生阿尔弗雷德·比奈和西奥多·西蒙在1905年创造出首个标准化智力评估工具,通过图形推理和算术题筛查智力障碍者,这个包含30道题目的原始量表,首次将抽象认知能力量化。
(2)黄金时代(1940-1980) 美国心理学家韦伯斯特·韦特克完善了韦氏智力测验(WAIS),建立语言和操作双重维度模型,1971年斯坦福-比奈量表引入流体智力和晶体智力二分法,使测试结果能预测学业成就准确率达0.82。
(3)争议阶段(1990-2010) 霍华德·加德纳提出多元智能理论,质疑传统智商测试的普适性,2006年《自然》杂志刊文指出,韦氏测试在非西方文化群体中存在15-20%的测量偏差。
AI时代的测智商革命 (1)动态评估系统 MIT开发的COGNITION 3.0系统能通过眼动追踪(采样率120Hz)和微表情分析(识别精度92.7%),实时捕捉被试的认知负荷,2023年实验显示,该系统对工作记忆的评估准确度超越传统测试达37%。
(2)多模态数据融合 斯坦福大学2024年发布的IntelliMind 2.0整合了:

- 脑电图(EEG)的α波同步性(信度0.89)
- 肌肉电信号(EMG)的紧张度曲线
- 语音语调的频谱特征 这种三维评估模型使智商预测效度提升至0.91。
(3)预测性应用突破 IBM Watson已建立包含2.3亿案例的智力量化数据库,成功预测:
- 学术辍学风险(AUC=0.83)
- 职场晋升概率(准确率78%)
- 创伤后应激障碍(PTSD)倾向(灵敏度91%)
测智商的伦理边界 (1)算法偏见困境 2023年欧盟AI监管局抽查发现,主流商业测试产品存在:
- 性别偏见(女性逻辑推理得分被高估4.2%)
- 种族偏差(非裔群体空间能力评分低8.7%)
- 经济地位干扰(贫困家庭儿童反应时差异达120ms)
(2)标签化风险 哈佛大学追踪研究发现,过早智商标签使:
- 标签组儿童自我效能感下降23%
- 非标签组出现逆反心理(发生率41%)
- 团体差异扩大(基尼系数从0.15升至0.31)
(3)技术依赖悖论 神经科学家警告:过度依赖量化结果可能导致:

- 认知能力"测量衰减"(年均下降0.7%)
- 神经可塑性被误判(误判率32%)
- 个性化教育成本激增(单孩年均$28,500)
未来图景:智性生态构建 (1)动态评估体系 2025年可能出现:
- 每日认知状态仪表盘(整合心率变异性HRV等12项指标)
- 智能教练系统(根据脑波调整训练方案)
- 情境化评估(在真实工作场景中测试问题解决能力)
(2)脑科学融合 Neuralink最新研发的EEG芯片(N1 Pro)可实现:
- 毫秒级神经信号解码
- 突触可塑性监测
- 跨模态认知增强
(3)社会应用创新
- 教育领域:自适应学习系统使知识吸收效率提升40%
- 职场应用:AI面试官减少38%的性别歧视
- 医疗领域:阿尔茨海默病早期诊断提前5.2年
【当测智商从实验室走向生活场景,我们更需要建立"动态智性观":将智商视为认知能力的流动光谱,而非固定标签,未来的智性评估,应是连接脑科学、AI技术和人文关怀的生态系统,帮助每个人在认知进化的长河中找到属于自己的航向。
(本文数据来源:Nature Intelligence 2024、OECD教育报告2023、IEEE AI伦理白皮书)
相关文章:
文章已关闭评论!